Sharing a Sequencer Set by Separating Execution from Aggregation
Summary
Typically, sequencers generate state roots for the blockchains they create blocks for. This requirement is resource heavy, and by simply removing it, we can share a single sequencer set across an arbitrary number of rollups. Instead of the sequencers executing transactions and generating state roots, rollup fullnodes do so either after they have reached finality on the data availability layer, or prematurely using the soft commitments provided by the shared sequencer set.
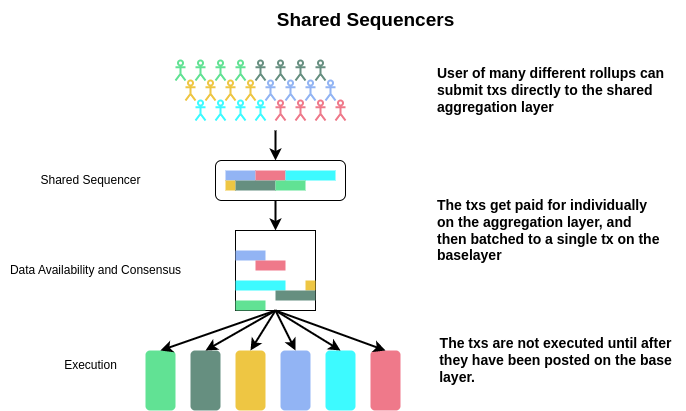
Most importantly, using a shared sequencer set makes deploying a decentralized sovereign rollup trivial, as the only prerequisites are a genesis state and a state machine running on at least one full node. Not only that, but now the logic typically required for aggregation is handled for the rollup, so the business logic can be isolated. This reduces the scope of the state machine and allows for the easy adaptation of existing execution environments into (currently pessimistic) rollups.
Intro
Thanks to the advent of modular blockchains, it is orders of magnitude easier and cheaper to launch a sovereign && secure blockchain. In many ways, deploying your own chain is a superior solution to deploying a smart contract. Developers can have full control over their execution environment, allowing them to design novel techniques for unprecedented scalability, trust minimization, and sovereignty that are simply not possible when deploying a smart contract on a generic blockchain.
However, unlike smart contracts, rollups do not as easily inherit the censorship resistance and liveness properties that can only come from a decentralized network. This is due to rollups also being dependent upon their own set of block producers (aka sequencers). Currently, almost all modern rollups use a single sequencer as a crutch. In that scenario, it only requires a single node to fail or censor.
While rollups could increase the decentralization of their sequencer set in theory, the overhead and cost of offchain organization, incentivization, and encoding the logic for such a feat quickly approaches that of deploying your own L1. If we are ever to get to one million sovereign rollups, then we have to find a solution to this problem.
Shared Aggregation
Shared aggregators enable rollups to have the censorship resistance and liveness properties of a decentralized sequencer set, the ease of deployment of a smart contract, and the sovereignty of an independent L1. They do this by running a middleware blockchain with a decentralized sequencer set. This blockchain accepts transactions directly from users for many different rollups, and then submits them directly to the baselayer in a single batch without applying any of the transactions to any specific state. All state transitions, transaction processing, and state proving mechanisms are handled after the transactions have been included on the baselayer by “lazy” rollup full nodes.
The concept of shared sequencers is very simple, but can be implemented in many different ways, each with their own tradeoffs. Below, we explore some of these possibilities and provide a clearer picture as to what shared aggregation would actually look like.
Paying for Gas
In order for the shared sequencer scheme described here to work, there has to be some mechanism for users to pay for the inclusion of their transactions into a block of the baselayer. While there are many different solutions to this, one simple one is to use the existing signature and address already included in almost all rollup transaction types to also pay for the gas on the sequencer layer. This would involve the sequencer layer to keep track of accounts similar to how most other blockchains do, and for users of a rollup to have funds to pay for gas on the sequencer layer. Another solution to paying for inclusion could involve a wrapper transaction on the sequencer layer, where anyone could pay for arbitrary data to be included.
Inheriting the Fork Choice Rule of the Sequencer Set
The rollups using the shared sequencer set can optionally inherit its fork choice rule. This would effectively involve the rollup full nodes being light clients to the shared sequencer set, and then checking some commitment that would indicate which rollup block is the correct one for a given height.
It’s important to note that inheriting the fork choice rule is not required for a shared rollup to use a shared sequencer. It would be possible to simply require the lazy rollup to process (note, not exactly execution!) of all block data/transactions for a given rollup that are posted on the base layer, not unlike what rollkit does now. This would allow for the rollup to more or less inherit the censorship and liveness properties of the baselayer instead of the sequencer layer, but has trade offs.
Atomic Inclusion of Transactions
Using a shared sequencer set, it is trivial to create a transaction type that ensures that many different rollup transactions are included atomically. The effect of such a primitive has yet to be explored, but would almost certainly have many useful applications, including bridging and MEV.
Swapping Shared Sequencer Sets
Notably, the separation of execution from sequencing allows for a rollup to swap or change the sequencer set with only a minor hardfork. This ability will encourage intense competition in the shared sequencer MEV space, and allow for a sovereign rollup to protect itself from the shared sequencers.
MEV
Shared sequencers can technically be separated from MEV. They are not required to execute transactions and it is not necessary that the transaction ordering they provide is final. However, considering that they have at the very least some influence over which transactions will be included in the next block, it is likely that MEV participants will be interacting with many, or perhaps running their own, shared sequencer sets.
Designs such as what is described in the ATOM 2.0 Interchain Scheduler should also be able to be built using a shared sequencer set, since we can atomically include rollup transactions in the shared sequencer layer.
It would also be interesting to see what services such as Skip or Mekatek could offer if they designed their own shared sequencer set. It might look similar to what Flashbots is doing with Suave (but hopefully they don’t rely on SGX or verbal promises to stay decentralized). Services such as Fairblock could also offer some sort of threshold encryption should that prove useful.
Shared Mempool
When using a shared sequencer, lazy rollups by default also share a mempool, which has proven to be one of the most bandwidth heavy components of a blockchain. With the advent of private mempools and advanced MEV architecture, the type of mempool a shared sequencer set uses could end up being a distinguishing feature.
Not a Universal Fit for All Rollups
Since execution is separated from aggregation, rollups that require state access to malleate transactions before including them on chain will require a more typical rollup architecture. An example of this would be rollups that have a block validity rule where all transactions included in the block are valid transactions that do not fail. If the rollup requires transaction malleation but does not require state access, then a special shared sequencer set could be created exclusively for rollups of that type. Examples of the latter would include something like Fuel v2 or a rollup with a private mempool.
Lazy Rollups
In programming language theory, lazy evaluation , or call-by-need ,[1] is an evaluation strategy which delays the evaluation of an expression until its value is needed (non-strict evaluation) and which also avoids repeated evaluations (sharing).[2][3] - Lazy evaluation wikipedia
In their essence, lazy rollups are the most minimal blockchains possible. They work by utilizing a different baselayer chain to publish a set of transactions before any header or state root is generated. After the transactions have been published, the lazy chain full nodes simply download the transactions, optionally apply a fork choice rule to select a subset of transactions, perform any arbitrary transaction processing, and apply those transactions to the state. Headers can then be generated and gossiped to light clients. As discussed above, lazy rollups by default share a mempool along with the sequencer set, further reducing the amount of resources, both in terms of infrastructure and engineering, that a lazy rollup team has to maintain.
Notably, all lazy rollups must be capable of handling invalid transactions. Meaning that rollups that require all transactions in the block be valid will need to use a different architecture.
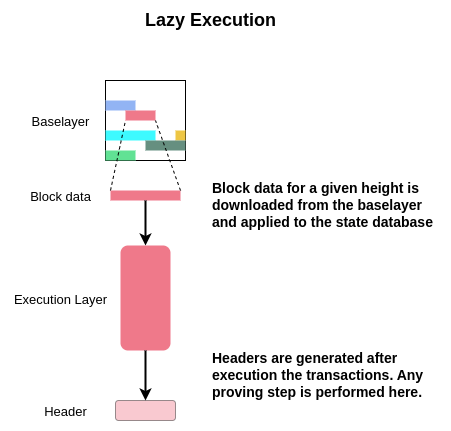
The Different Types of Lazy Rollups
Pessimistic rollups, at least how I’ve heard Dr. Mustafa Al-Bassam describe them, are rollups without any mechanism to prove the state of that chain. Pessimistic rollups therefore do not perform any additional steps to those described in the above figure. They simply download and execute the transactions. Similar to the monolithic L1s of yesteryear, these chains require running full nodes to be convinced that a given state root is actually valid.
Optimistic rollups have to have some mechanism to prevent fraud proof spam. Typically, this is done by the sequencer including a signature over the block with some commitment over the state. Since we are separating aggregation from execution, the sequencers cannot be responsible for this. While there are likely other solutions, one is to perform the same step as before, but after the block data has been posted and using a different committee.
Validity rollups work in a very similar way to how pessimistic rollups work, except arbitrary parties generate validity proofs over the new state. Notably, lazy validity rollups differ from existing validity rollups because the entire block data is posted to the baselayer instead of only the state diffs. This is less efficient in most cases.
Reduced State Machine Scope
Currently, every type of rollup with a decentralized sequencer set has to have some logic to maintain the state of that sequencer set. Since this state is now handled for the execution environment by the shared sequencer set, it no longer has to maintain that logic in its state machine. In the cosmos-sdk, this means removing most if not all of the staking, slashing, and distribution modules state bloat.
Beyond reducing state bloat and engineering efforts, this reduction in state machine scope makes it significantly easier to adapt existing execution layers, using their native implementations.
Adaptation of Existing Execution Layers
As mentioned in the above section, due to the minimization of responsibilities for lazy rollups, adapting the native implementations of existing execution layers is much easier. The only tasks that a lazy rollup must do is download some block data, perform basic checks over it, and apply it to the state.
If we can adapt the native implementations of existing execution environments, then that also means that it will be easier to adapt the tooling and infrastructure for those environments.
For example, if we wanted to create an EVM based lazy rollup, instead of using the ethermint module in an application connected to rollkit, or we could use a native EVM execution environment such as Erigon or Reth. Depending on which implementation we adapt, we should also be able to adapt critical infrastructure compatibility such as the ethereum JSON api, turbo sync, and event system.
Deploying a Lazy Rollup on a Shared Sequencer Set
Deploying a lazy rollup is arguably simpler than deploying a set of smart contracts. The only requirements are to pick a genesis state, a state machine, and a chain-id that follows the format accepted by a given shared sequencer set. After a single full node is running, users can begin submitting their transactions directly to the shared sequencer set.
Soft Execution

Assuming the happy most probable case, waiting to execute transactions before they are posted on the base layer is incredibly wasteful, and bottlenecks the UX. To unlock a web2 equivalent UX, the shared sequencers a lazy rollup is using can provide fast soft commitments. These soft commitments provide some arbitrary promise of the final ordering of transactions, and can be used to create prematurely updated versions of the state. As soon as the blockdata has been confirmed to be posted on the baselayer, the state can be considered final.
MVP
A portion of what is described above has been implemented as a very crude proof of concept here. It currently (Jan 1st 2023) consists of a normal cosmos-sdk and tendermint based chain, that can accept transactions with arbitrary chain-ids in the following format: “shared-aggregator-chain-id|lazy-rollup-chain-id”. Using chain-ids of that format, it keeps track of the nonces used per lazy rollup. Transactions that are not using only the “shared-aggregator-chain-id”, are not executed, but they are included in a block. These combined can then be submitted to the base layer. As of celestia-app v0.11.0, Celestia does not yet have batched transaction functionality. However, it should be in either v0.12.0 or v0.13.0, as we already have a PR up.
As briefly mentioned above, the shared sequencer set can run many different consensus algorithms, and, for this use case, tendermint is far from ideal. After decentralized sequencing is completed on rollkit, the same application written for the MVP would work with that. Alternatively, we could use something much lighter, such as what is described here, or if we use a modified version of tendermint with the prevote step removed.
Conclusion
One of Celestia’s main goals is to empower the social consensus of communities with the ability to create their own secure && sovereign blockchains. Deploying a secure sovereign rollup should be as easy as deploying a smart contract. While the architecture described above does not work universally for all rollups, shared sequencers could contribute meaningfully to that vision. Not only does it enable arguably the easiest sovereign blockchain deployment ever, but it does so in a decentralized way. It also significantly reduces the scope of the rollup by performing aggregation for it. Both of these properties contribute to making smaller chunks of state into their own blockchain actually viable. The more isolated the state, the easier it is to hardfork. The easier it is to hardfork, the more sovereign it is.
As a notable bonus, the shared sequencer design is conducive to dramatic UX optimizations and is incredibly flexible in both its design and functionality. Features such as MEV services, varying speed/confidence of soft commitments, transaction malleation, and even sovereign oracles, could all exist across many different shared sequencers.
Related to:
Decentralized Rollup Sequencing as a Service via Interchain Security - Nick White