This post was co-authored with Nima Vaziri (@NimaVaziri). Special thanks to John Adler (@adlerjohn), Mustafa Al-Bassam (@musalbas), Ismail Khoffi (@ismail) and other members of the Celestia team for their reviews.
HackMD mirror: Woods Attack on Celestia - HackMD
Introduction
This document describes a denial-of-service (DoS) attack that targets rollup nodes trying to sync with the latest state of a rollup on Celestia. While bootstrapping, these nodes download the headers of all past rollup blocks to determine the canonical tip of the rollup chain. Thus, the time required for the completion of bootstrapping depends on the number of rollup blocks previously published on the parent chain. In this context, attackers could delay bootstrapping considerably by publishing many invalid rollup blocks on the parent chain and forcing syncing nodes to download all of their headers.
Rollups on Celestia is prerequisite for a better understanding of this article which assumes a basic knowledge of the rollups and namespaces.
Section Background explains how rollup-specific messages are posted on the parent chain in Celestia. Section Attack Description gives a detailed description of how the attacks exploit the mechanism explained in Section Background to spam the parent chain with invalid rollup blocks. Sections Costs and Mitigation focus on the attacker’s costs and the mitigations strategies for the attack respectively.
Background
In Celestia, the parent chain does not host any contract that interprets or processes rollup-specific messages. It is used by the rollup nodes solely as an ordering and data availability service for their messages. Consensus nodes select messages sent by rollup nodes using a fee-market and accept any message that is paid for. As they do not validate the states within rollup blocks, consensus nodes cannot distinguish or censor invalid messages submitted to the parent chain.
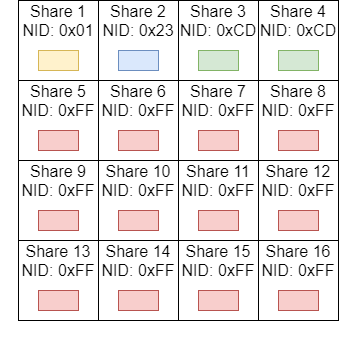
Parent chain blocks consist of multiple shares each associated with a namespace ID (NID) and arranged in a square. Colored rectangles represent the messages published for the namespace IDs of the shares. In the given example, shares 5 to 16 are spammed by invalid messages (shown in red) posted for the namespace ID (0xFF) of a rollup under attack.
Each rollup is associated with a unique namespace ID which signifies to the consensus nodes the location of the rollup-specific messages within a parent chain block. These messages are structured to first list the contents of the rollup block headers, e.g state roots, and then the transactions contained in these block. To download the past rollup blocks included in a parent chain block B, rollup full nodes would first ask for the messages within B with their rollup’s namespace ID from the consensus nodes. Similarly, rollup light clients would ask for the first few bytes of the same messages corresponding to the rollup block headers. Upon receiving the respective messages from the consensus nodes, rollup nodes can verify that they were returned all messages with the queried namespace ID using the Namespaced Merkle Trees.
To bootstrap with their rollup, new full nodes retrieve headers and transactions contained within all past rollup blocks published on the parent chain. Thus, they can process all of the older transactions, verify the validity of the blocks and determine the canonical rollup chain and the latest application state. On the other hand, new light clients download only the headers of past rollup blocks published on the parent chain. Using past validity or fraud proofs generated for these blocks, they can detect the invalid ones and determine the canonical rollup chain consisting of the valid blocks.
Given the explanations above, there are multiple stakeholders that can potentially be affected by the attack:
- Consensus (parent chain) nodes
- Rollup full nodes under attack
- Rollup light clients under attack
- Attacker: Any entity that can post rollup blocks to the parent chain can be an attacker, such as malicious full nodes in a rollup.
Attack Description
In the descriptions below, we assume that the attackers target the rollup full nodes and light clients belonging to a certain rollup with a known namespace ID.
Attack on Rollup Light Clients
In this version of the attack, attacker pays consensus nodes to spam each parent chain block with headers of invalid rollup blocks. Suppose there are k blocks on the parent chain and each such block consists of n fixed sized shares that can be assigned a namespace. Then, the attacker publishes the header of an invalid rollup block at each share and sets their namespace IDs to be same as the rollup. Hence, when a new light client attempts to bootstrap, it will receive rollup block headers from all of the shares within each parent chain block, and will have to check the validity of the state roots within all of them using validity or fraud proofs. Assuming that a single state root can be checked in constant time, identifying all of the invalid rollup blocks and finding the canonical rollup chain will take time on the order of k \times n, i.e the total size of the parent chain at the given moment. This is equivalent to having rollup light clients download all of the data within the parent chain.
Attack on Rollup Full Nodes
In this version, attacker pays consensus nodes to spam each parent chain block with not only the headers of invalid rollup blocks but also their transactions. For this purpose, it reserves all of the n shares in each parent chain block for the namespace ID of the rollup and fill them with headers and transactions of invalid rollup blocks. Thus, even though a syncing rollup full node will download and process O(k \times n) transactions, equivalent to the total size of the parent chain, the number of valid rollup blocks verified by the node will be a much smaller fraction of the downloaded blocks.
Costs
When rollup light clients are under attack, they have to download O(n) messages from each parent chain block, where n is the total number of shares per block. Considering that a light client for the parent chain downloads only O(\sqrt{n}) messages per block for data availability checks, downloading O(n) messages is a large fixed cost for light clients syncing with a rollup. On the other hand, even though rollup full nodes can be expected to process as many as O(n) rollup-specific transactions per parent chain block, only a small fraction will end up in the canonical rollup chain under attack.
For a numerical estimate, if (i) there are n=1024 shares that can be dedicated to a given namespace in a Tendermint block, (ii) each share costs \$9 in transaction fees (\$9 was calculated to be on par with Ethereum transaction fees), and (iii) there is one block per minute, a rough estimate for the attacker’s cost would be 1024∗9∗(30∗24∗60)\approx400 million USD for an attack period of four weeks during which there will be k\approx43,000 parent chain blocks. This is not only a reasonable cost for a billion dollar adversary, e.g, a nation state, but also a serious DoS vector for rollup light clients as they will have to download the entirety of 43,000 parent chain blocks spammed with invalid rollup-specific messages.
To see the effect of the attack above on the bootstrapping time, suppose one year worth of Celestia blocks can be downloaded by light clients in a single day when they receive messages from only O(\sqrt{n}) of the shares per block. Then, downloading the entirety of 43,000 blocks spammed by the attacker would require approximately 3 extra days on top of the original 1 day, enough to dissuade most light clients from ever following the rollup under attack!
Mitigation
One way bootstrapping rollup nodes can mitigate the attack is by downloading rollup block headers from full nodes via the rollup’s peer-to-peer network. This way, they can avoid scanning the parent chain and downloading messages from every share. However, this solution cannot be implemented by rollup light clients that rely on the parent chain to receive rollup-specific messages. Moreover, it might facilitate other DoS attacks on these syncing light clients by malicious rollup full nodes. (These can potentially be avoided using privacy preserving spam protection methods on the network level.)
Another mitigation strategy is to rate limit the number of shares that can be reserved for a single namespace within each parent chain block. For instance, when the total number of shares per parent chain block is n, rollup-specific messages with a single namespace ID can be restricted to occupy at most \sqrt{n} shares per block. In this case, even a light client under attack would have to retrieve messages from at most O(\sqrt{n}) shares per parent chain block. As light clients already download O(\sqrt{n}) messages per parent chain block for data availability checks under normal circumstances, this restriction removes the DoS vector caused by the attacks as compared to the normal operation of the rollup.
The proposed restriction on the number of shares per NID can be implemented in multiple ways. For instance, the price of reserving a new share for a given NID can be made exponentially large as the number of shares with that NID grows. It can also be enforced directly by rollup nodes that would refuse to download messages from more than \sqrt{n} shares per parent chain block.
Rollups that are willing to pay for more space can always use multiple namespace IDs for their messages to circumvent the constraint on the number of shares per namespace. However, this comes with a greater DoS risk for the syncing nodes, implying a tradeoff with the benefits of more data storage.
When calculating the attacker’s costs in Section Costs, we ignored the fact that the attacker’s funds could be slashed by the rollup nodes for publishing invalid blocks on the parent chain. However, as the balances of rollup nodes are stored as part of the application state in Celestia, attacker can be penalized only if it has already locked funds within the state. If this is not the case, rollup nodes can always reject blocks by the attacker; however, this does not change the fact that rollup nodes would have to download these blocks first (at least the signatures to verify the identity of the staked rollup node). Thus, financial penalties do not necessarily provide a mitigation for the syncing rollup nodes in the context of the attacks above.